TALQuモデル製作の実験も兼ねて、現在、ITAコーパス読み上げ音声を製作しています。
ITAコーパスは、音声合成の元となる声を収録するための文章集のひとつです。これまでに公開されていたコーパスはライランス関係がややこしいものが多かったのですが、こちらのITAコーパスは、使用料0円、パブリックドメイン! 誰でも安心して使え、作ったものも自由に配布できるようになっています。
このITAコーパスを読み上げて録音した音声があれば、これから音声合成ソフトなどを開発しようとしている人の役に立つはず。ということで、あみたろの声素材工房としてITAコーパス読み上げ文章を公開したくて、現在作業を続けています。
ITAコーパスは、全部で424文。既にひととおりの収録は完了していて、現在は、セリフ素材のように、ひとつずつリップノイズを除去したり、たくさんのテイクの中からベストなテイクを選んだり、時には破裂音のつなぎ目などで音声と音声をがっちゃんこしたり…と、細かい編集作業を進めています。
完全一発録音のCoeFontの収録と違って、前半と後半それぞれのベストテイクを合体する、ということができるので、息が続かないような長文や難読連発の文章でも、ちゃんと安定した音声に仕上げられるので助かっています。そうやってとことんこだわれるからこそ編集にものすごく時間がかかってしまうのは、難点といえば難点かも?
424文を納得いくまで録音した結果、音声ファイルは全部で3185個になりました。
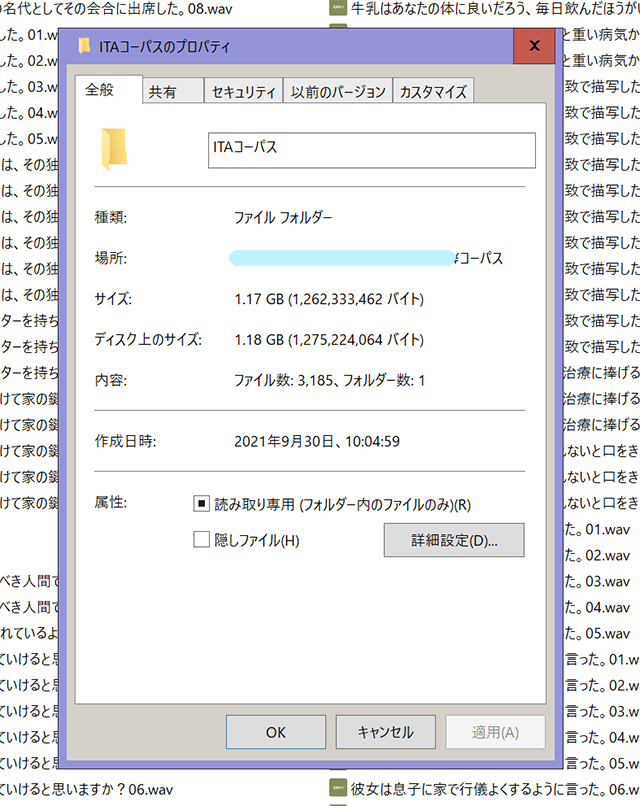
すらっと読めるものは3テイク程度、苦戦気味のもので15テイク程度とばらつきはあるけど、平均すると一文あたり7.5テイク。体感としては、CoeFontCLOUDの収録とそんなに変わらないイメージです。
今回は、とにかく安定感重視。すべての音を正確に発音し、読む速度を一音一音変わらず安定させ、声を裏返らせず…と、音素のラベリングを自動でやる時に使いやすく、聴覚のみで内容が理解しやすい読み上げ声を作れるように、と意識して録音しました。
もっと自然な話し声やいわゆる萌え声も需要はあると思うけど、一番最初に公開するならやっぱり、趣味レベルの研究にも使いやすくて、作ったものが誰かの役に立つような方向性が良いかな、って。あみたろの声素材工房のユーザーさんは、音声ファイルさえあれば本当にいろいろな方向に利用してくださるので!
このITAコーパス読み上げ音声をうまく利用していただければ、CoeFontよりも品質の良い音声合成も作れると思います。(CoeFontは自動ラベリングなので、ラベリングを手動にするだけでも大きく変わるはずです)
ITAコーパス読み上げ音声が完成したら、一般公開しつつ、これを元にTALQuモデルを一度自分で作ってみて、いい感じなら同じ声でTALQuコンテスト優勝特典の大量収録に進む予定です。がんばります!

コメント